Abstract
Generating high-fidelity 3D head avatars from a single image is challenging, as current methods lack fine-grained, intuitive control over expressions via text. This paper proposes SIE3D, a framework that generates expressive 3D avatars from a single image and descriptive text. SIE3D fuses identity features from the image with semantic embedding from text through a novel conditioning scheme, enabling detailed control. To ensure generated expressions accurately match the text, it introduces an innovative perceptual expression loss function. This loss uses a pre-trained expression classifier to regularize the generation process, guaranteeing expression accuracy. Extensive experiments show SIE3D significantly improves controllability and realism, outperforming state-of-the-art methods in identity preservation and expression fidelity on a single consumer-grade GPU.
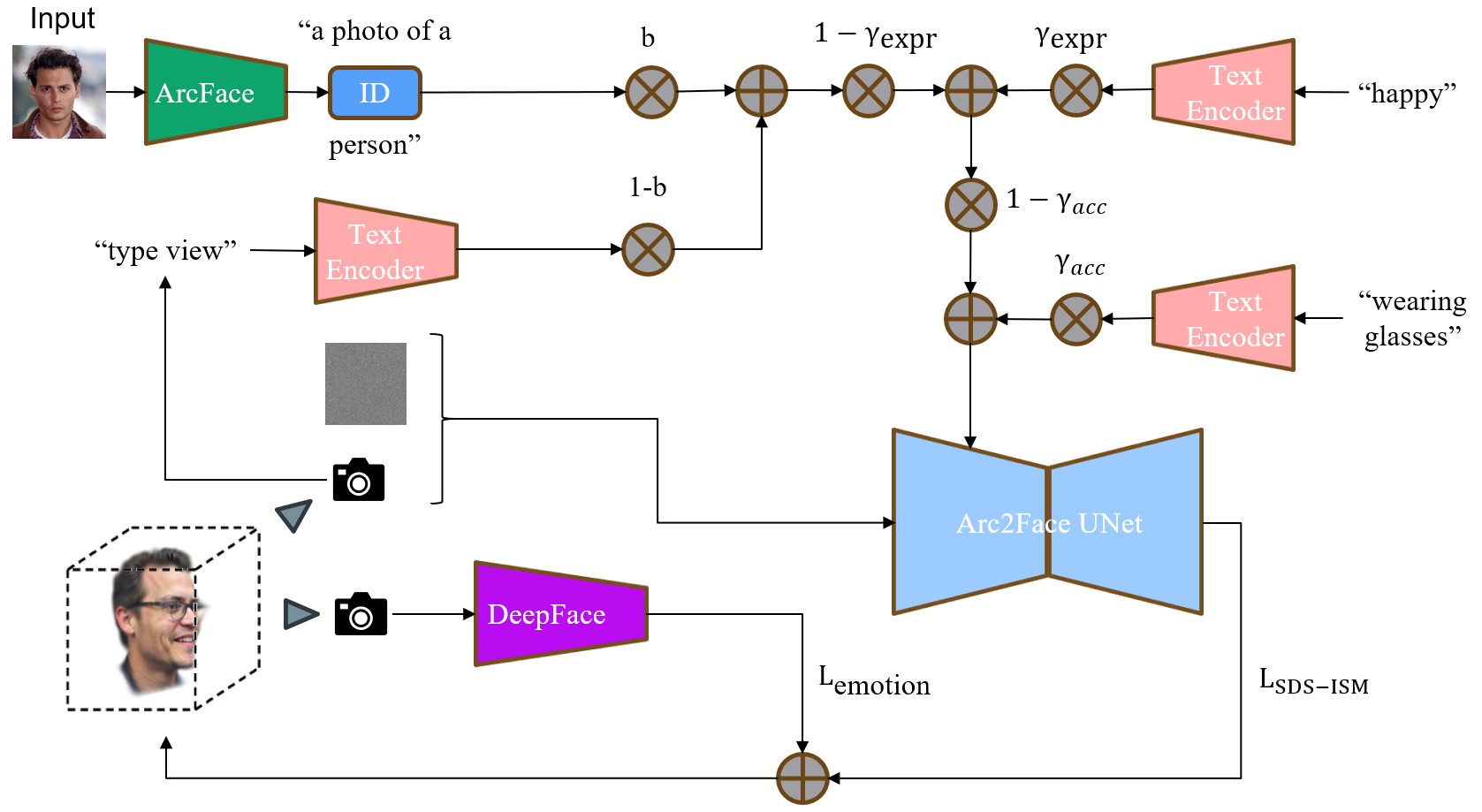
Overall architecture of the SIE3D framework.

Qualitative comparison with other competitive methods.
